Tarama Bütçesi (Crawl Budget)

Internet üzerinde çok fazla web sitesi ve web sayfası bulunuyor, bu web siteleri arama motorları tarafından düzenli olarak ziyaret ediliyor ve dizinlere ekleniyor, tabii ki arama motorları için bu işlemleri gerçekleştirmek bir sunucu kaynağı harcaması oluşturuyor.
Kaynağın verimli kullanılması için web sitelerinin sayfaları önceliklendiriliyor, tarama (crawl) işlemi bu önceliklendirmeye göre gerçekleşiyor. Burada tarama bütçesi kavramı devreye giriyor, bu kavramı basit bir şekilde Google botlarının indeksleyebileceği URL sayısı ve tarama sıklığı olarak tanımlayabiliriz.
Tarama Bütçesinin Google Botları İçin Anlamı Nedir?
Eğer web sayfaları paylaşıldığı gün içerisinde Google botları tarafından indekse alınıyorsa tarama bütçesi kavramı çoğu web yöneticileri tarafından endişelenecek bir durum değil. Aynı şekilde web sitesi birkaç binden daha az sayıda URL içeriyorsa Google botları tarafından çoğu zaman etkili bir şekilde taranır.
Arama motoru botları için taranacak sayfaların önceliklendirilmesi büyük URL sayısına sahip web sitelerinde ya da parametre bazında otomatik sayfa üreten web sitelerinde daha önemlidir.
Crawl Budget (tarama bütçesi) kavramını tanımlayan 2 diğer alt kavram;
Crawl Rate Limit (Tarama Hızı Sınırı)
Crawl rate limit Google botlarının siteyi tarama sayısını ve taramalar arasındaki beklenecek süreyi temsil eder. Birkaç faktöre göre tarama hızı artalabilir veya azalabilir.
- Crawl Health: Eğer web sitesi hızlı bir şekilde isteklere cevap verebiliyorsa tarama hızı artış gösterebilir ve tarama için daha fazla bağlantı kullanılabilir, tam tersi şekilde site geç yanıt verirse, hızı düşerse ve sunucu hataları varsa tarama hızında azalma görünebilir, botlar sayfaları daha az tarar.
- Tarama Limiti: Google’ın gelişmiş algoritması siteleri tarama hızını kendisi belirler, bunu yaparken bant genişliğini zorlamadan gerçekleştiriyor. Yine de web sitesi sahipleri Google botlarının çok fazla sayıda istek attığını düşünüyorsa taramalarını Search Console üzerinden azaltabilirler, tam tersi şekilde yüksek limitler belirlemek ise taramayı otomatik olarak artırmaz.
Crawl Demand (Tarama Talebi)
Tarama hızı sınırına (Crawl Rate Limit) ulaşılmasa bile tarama talebi olmadığı sürece Google botlarının etkisi düşük olacaktır. Aşağıdaki 2 faktör taranma talebinde önemli rol oynuyor.
- Popularity (Popülerlik): Internet üzerinde popüler olan sayfalar taranma sıklığının fazla olup sayfaların hep güncel halinin indekslenmesine eğilimli olurlar.
- Staleness (Yıpranmışlık): Google sistemleri dizine indekslenmiş sayfaların bayatlamış olmalarını engellemeye çalışır.
İçeriği yenilenen sayfalar botlar için tarama talebi oluşturabilir, yani Google botlarının websitesini ziyaret etmesini tetikleyebilir.
Web Sayfalarının Ziyaret Edilme Periyodu Neye Göre Belirleniyor?
Web sayfalarının tekrar ziyaret edilmesi sayfa üzerindeki yapılan son değişikliklere bağlı. Sayfalardaki değişiklikler yapılandırılmış verilerle (structured data) veya sayfa üzerindeki tarih bilgileriyle belirtilebilir.
Eğer uzun zaman boyunca sayfa üzerinde bir değişiklik yapılmamışsa botlar sayfayı tekrar ziyaret etmeyi gerek görmeyebiliyor. Bu durumun içeriğin veya sayfanın kalitesiyle bir alakası yok, sayfanın ve içeriğin kalitesi gayet iyi olabilir fakat botların sayfayı tekrar ziyaret etmesini gerektirecek bir değişiklik sebebine ihtiyaçları var.
Crawl Budget’ı Etkileyen Faktörler
Düşük değere sahip olan ve kalitesiz URL’ler taramayı ve indekse almayı olumsuz etkiler.
- Kopya İçerik
- Soft 404 Sayfaları
- Yönlendirme Sayfaları
- Düşük Kalite ve Spam içeriğe Sahip Sayfalar
- Sayfa Filtreleri (Sayfalarda bulunan fiyat, renk, marka filtrelerine tıklandığında URL’e parametre eklenen yapılar Crawl Budget’i etkileyebilir.)
Tarama sitelerin arama sonuç sayfalarına (SERP) giriş noktasıdır, verimli bir tarama için Crawl Budget’ı optimize etmek gerekir. Sunucu kaynaklarını boşa harcayan sayfalar tarama bütçesini gereksiz kullanır, botların tarama etkinliklerini düşürürler.
Hangi Web Siteleri İçin Tarama Bütçesi Dikkate Alınmalıdır?
- İçeriği haftada 1 sıklıkla değişen 1 milyondan fazla benzersiz sayfaya sahip olan web siteleri,
- İçeriği her gün değişen 10 binden fazla benzersiz sayfaya sahip olan orta ölçekli ve büyük web siteleri,
- URL’lerin büyük bir kısmı Search Console üzerinde Keşfedildi, şu anda dizine eklenmiş değil olarak uyarı veren web siteleri.
Web sayfaları yayınlandığı gün indeksleniyorsa Crawl Budget tarafında bir sorun olduğu anlamına gelmez.
Not: Yukarıda belirtilen URL sayıları ortalama olarak web sayfalarını sınıflandırmak için temsili değerlerdir, bire bir eşit değerler değildir.
Tarama Bütçesi Nasıl Arttırılır?
Google web sayfalarını taramak için kaynak ayırırken web sitelerinin popülerliğine, benzersizliğine (kopya içerik olmadan özgün içerik olmasına), içerik kalitesine ve sayfa performansına dikkat ediyor. Crawl Budget’ı artırmak için bu konulara dikkat edin.
Crawl Budget Nasıl Optimize Edilir?
Google için taranması uygun olan URL’leri kullanın, Google gereksiz sayfaları sürekli tararsa botlar sitenin geri kalanının taranmaya gerek olmadığına karar verebilir, ayrıca web sitesinin yüklenme performansı da Crawl Budget’ı etkileyen faktörlerden biridir.
Kopya İçerik Sayfalarının Kaldırın
Kopya sayfaları ortadan kaldırın ve benzersiz sayfalara odaklanın, canonical etiketi kullanımına dikkat edin.
URL’leri Robots.txt ile Bloklayın
Site için önemli olan ama indekslenmesine gerek olmayan sayfaları robots.txt üzerinden bloklayın.
Not: Sayfaları bloklamak için noindex etiketi yerine robots.txt dosyasını kullanın, URL’lerin dizine eklenme olasılığını önemli ölçüde azaltır. Noindex etiketi kullanılan sayfalarda Google noindex etiketini gördüğünde durur fakat tarama zamanı boşa harcanmış olur. Robots.txt’yi Google tarafından indekslenmesini hiç istemediğiniz sayfalar için kullanın.
Kaldırılan Sayfalara 404 veya 410 Durum Kodlarını Döndürün
Kaldırılan sayfaların silindiğini belirtmek için 404 veya 410 durum kodunu kullanın.
Soft 404 Sayfalarını Kaldırın
Soft 404 sayfaları Google botları tarafından taranmaya devam ediyor ve tarama bütçesinden harcıyor.
Search Console üzerindeki Kapsam bölümünden soft 404 hatalarını görüntüleyebilirsiniz.
Site Haritasını Güncel Tutun
Google site haritasını düzenli olarak inceliyor, bu yüzden web sitesinde yeni bir sayfa yayınlandığında bu sayfanın site haritasında da yer aldığından emin olun. Site haritasında içeriğin son güncellenme tarihini belirten <lastmod> etiketini de kullanın.
Yönledirme Zincirlerini (Redirect Chains) Engelleyin
Çoklu yönlendirme zincirleri taramayı olumsuz etkiliyor, yönlendirme zincirlerini engelleyin.
Sayfa Yüklenme Performansını İyileştirin
Sayfalar hızlı yüklenir ve render alırsa Google siteden daha fazla içerik okuyabilir.
Sitenin Taranmasını İzleyin
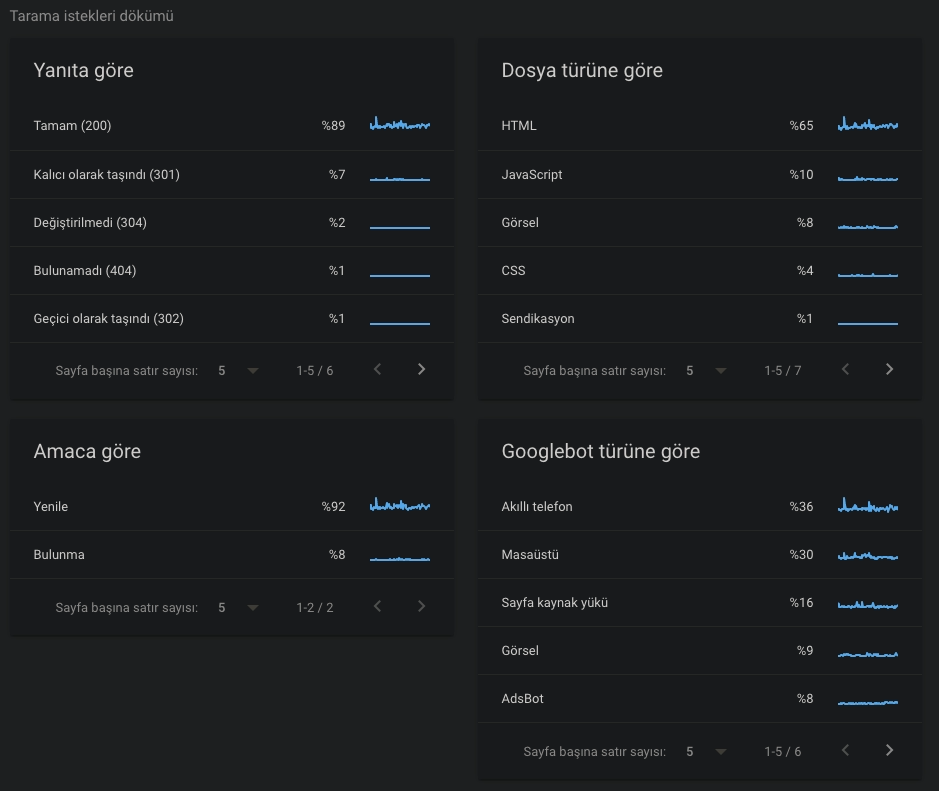
Web sayfası taranırken kullanılabilirlik sorunu olup olmadığını Search Console üzerinden takip edin, taramanın daha verimli olması için gereken teknikleri uygulayın.
Search Console üzerinde Ayarlar > Tarama istatistikleri alanından tarama istatistiklerinizi takip edin.

Kısaca özetlemek gerekirse Google kendi sunucu kaynaklarını en verimli şekilde kullanabilmesi için web sayfalarını otoritesine göre bütçelendiriyor ve gereksiz bir şekilde sürekli sayfaları tarayıp kaynak tüketiminin önüne geçmeye çalışıyor.
Kaynak
https://developers.google.com/search/blog/2017/01/what-crawl-budget-means-for-googlebot
https://developers.google.com/search/docs/advanced/crawling/large-site-managing-crawl-budget