What is Crawl Budget?

There are many websites and web pages on the Internet, these websites are regularly visited by search engines and added to directories, of course, performing these operations for search engines creates a server resource expenditure.
In order to use the resource efficiently, the pages of the websites are prioritized, and the crawling process takes place according to this prioritization. This is where the concept of crawl budget comes into play, which we can simply define as the number of URLs Google bots can index and the crawl frequency.
What Does Crawl Budget Mean for Google Bots?
If web pages are indexed by Google bots on the same day they are posted, the crawl budget concept is not something to worry about by most webmasters. Likewise, if the website contains fewer than a few thousand URLs, it is often effectively crawled by Google bots.
Prioritizing the pages to be crawled for search engine bots is more important in websites with large URL numbers or in websites that automatically generate pages on the basis of parameters.
Two other sub-concepts that define the concept of Crawl Budget;
Crawl Rate Limit
The crawl rate limit represents the number of times Google bots crawl the site and the time to wait between crawls. The scanning speed may increase or decrease depending on several factors.
- Crawl Health: If the website is able to respond to requests quickly, the crawl speed may increase and more connections can be used for crawling, on the contrary, if the site responds late, its speed decreases and there are server errors, the crawl speed may decrease, the bots crawl the pages less.
- Crawl Limit: Google’s advanced algorithm determines the crawling speed of the sites itself while doing this without forcing the bandwidth. However, if website owners think that Google bots are throwing too many requests, they can reduce their crawl through Search Console, conversely, setting high limits will not automatically increase crawls.
Crawl Demand
Even if the Crawl Rate Limit is not reached, the effect of Google bots will be low unless there is a crawl request. The following 2 factors play an important role in the scan request.
- Popularity: Pages that are popular on the Internet have a high frequency of crawling and tend to always index the current version of the pages.
- Staleness: Google systems try to prevent indexed pages from becoming stale.
Pages whose content is refreshed can generate a crawl request for bots, that is, they can trigger Google bots to visit the website.
How is the Visitation Period of Web Pages Determined?
Re-visiting web pages depend on the last changes made on the page. Changes to pages can be indicated by structured data or date information on the page.
If no changes have been made on the page for a long time, the bots may not find it necessary to visit the page again. This has nothing to do with the quality of the content or the page, the quality of the page and the content may be fine, but the bots need a reason for the change to revisit the page.
Factors Affecting Crawl Budget
Low-value and poor-quality URLs negatively affect crawling and indexing.
- Duplicate Content
- Soft 404 Pages
- Redirections
- Pages with Low Quality and Spam content
- Page Filters (When clicking on the price, color, and brand filters on the pages, the structures that add parameters to the URL may affect Crawl Budget.)
Crawling is the entry point to search results pages (SERP) of site URLs. It is necessary to optimize Crawl Budget for efficient crawling. Pages that waste server resources use the crawl budget unnecessarily and reduce the crawling activities of bots.
For Which Websites Should Crawl Budget Be Considered?
- Websites with more than 1 million unique pages whose content changes weekly,
- Medium to large websites with more than 10 thousand unique pages whose content changes daily,
- The majority of URLs are Discovered in Search Console, websites that are currently warning as not indexed.
If web pages are indexed on the day they are published, it does not mean that there is a problem with Crawl Budget.
Note: The URL numbers mentioned above are representative values for classifying web pages on average, not one-to-one values.
How to Increase Crawl Budget?
When allocating resources to crawl web pages, Google pays attention to the popularity of websites, uniqueness (original content without duplicate content), content quality, and page performance. Pay attention to these issues to increase Crawl Budget.
How to Optimize Crawl Budget?
Use URLs that are suitable for crawling for Google, if Google constantly crawls unnecessary pages the bots may decide that the rest of the site does not need to be crawled, also the loading performance of the website is one of the factors that affect the Crawl Budget.
Remove Duplicate Content Pages
Eliminate duplicate pages, focus on unique pages and pay attention to use canonical tags.
Block URLs with Robots.txt
Block pages that will be used on the site but do not need to be index with robots.txt.
Note: Use robots.txt instead of the noindex tag to block pages, significantly reducing the likelihood of being indexed URLs. On pages that use the noindex tag, Google stops when it sees the noindex tag, but the crawl time is waste. Use robots.txt for pages you never want to be indexed by Google.
Return 404 or 410 Status Codes to Removed Pages
Use status code 404 or 410 to indicate that removed pages which won’t use anymore.
Remove Soft 404 Pages
Soft 404 pages continue to be crawled by Google bots and spend their crawl budget.
You can view soft 404 errors on the Search Console Page Indexing report.
Keep Sitemap Updated
Google reviews the sitemap regularly, so whenever a new page is published on the website, make sure it is included in the sitemap as well. Also use the <lastmod> tag, which specifies the date the content was last updated in the sitemap.
Remove Redirect Chains
Multiple redirect chains deface crawling, block redirect chains.
Improve Page Load Performance
If pages load and render fast, Google can read more content from the site.
Monitor Site Crawl
Follow up on Search Console if there is a usability problem while crawling the web page, and apply the necessary techniques to make the crawling more efficient.
Track your crawl statistics from Settings > Crawl statistics on Search Console.

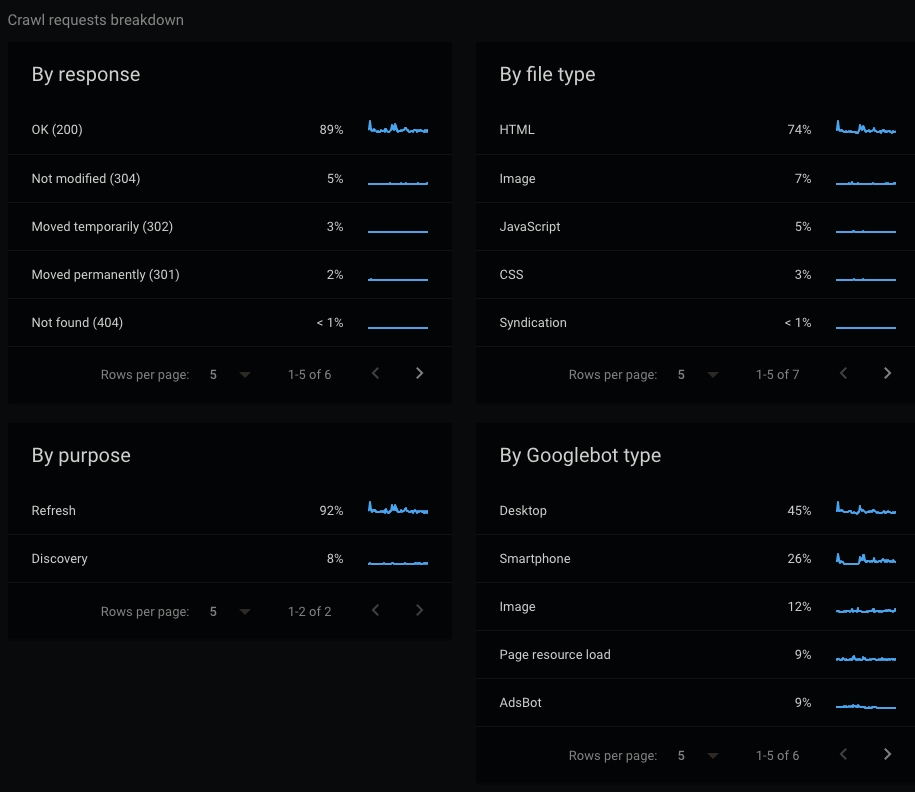
To summarize, Google budgets web pages according to its authority in order to use its own server resources in the most efficient way and tries to avoid resource consumption by constantly scanning pages unnecessarily.
Source
- https://developers.google.com/search/blog/2017/01/what-crawl-budget-means-for-googlebot
- https://developers.google.com/search/docs/advanced/crawling/large-site-managing-crawl-budget