What are AI Guardrails?
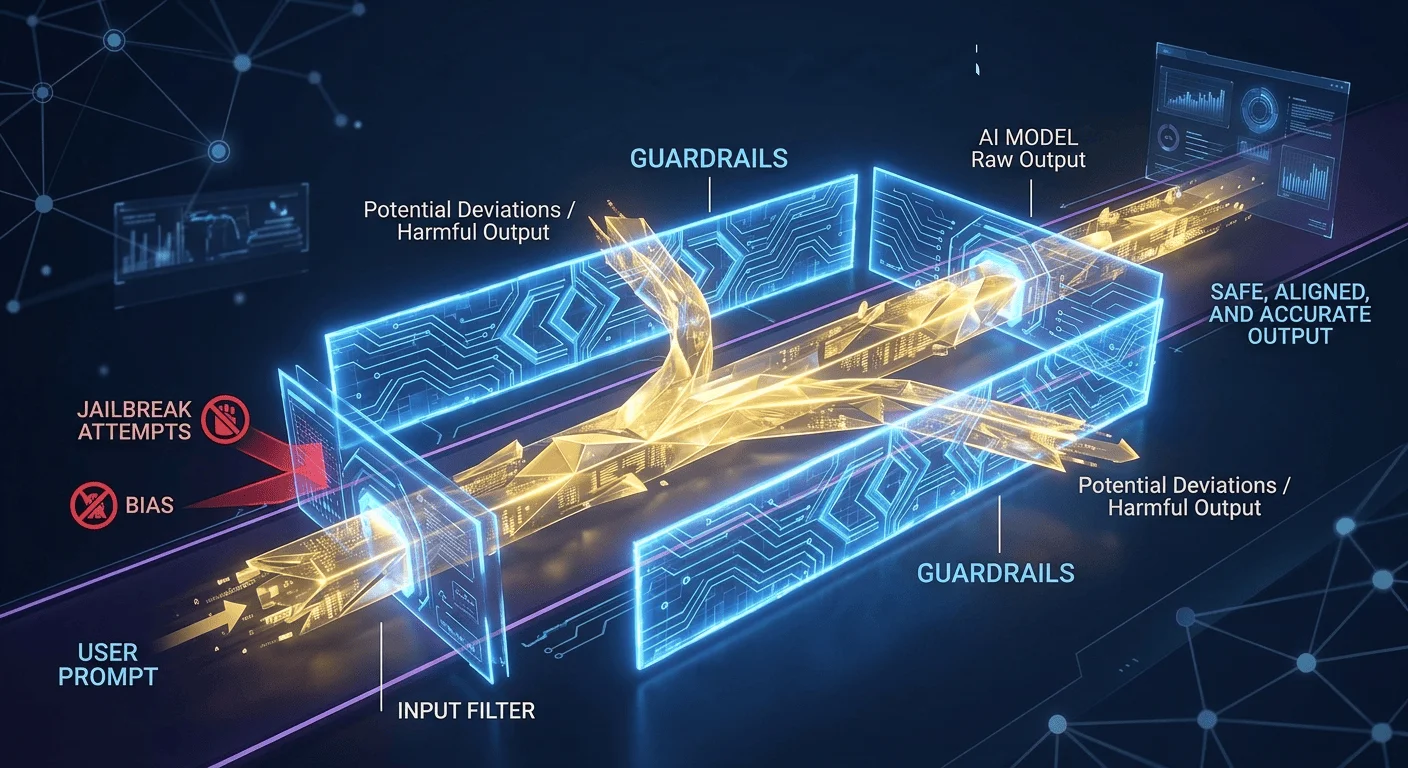
In the context of Artificial Intelligence, Guardrails are a set of safety measures, architectural constraints, and filtering layers designed to ensure that an AI model operates within predefined ethical, legal, and operational boundaries.
Think of them as the physical guardrails on a highway: they don’t steer the car for you, but they prevent it from veering off a cliff or into oncoming traffic.
How AI Guardrails Work
Guardrails typically act as an intermediary layer between the user and the AI model. They monitor both the input (the user’s prompt) and the output (the model’s response) in real-time.
Input Guardrails (Pre-processing)
These analyze a user’s request before it ever reaches the core model. They are designed to:
- Block Malicious Intent: Identifying “jailbreak” attempts or prompt injections.
- Filter Sensitive Data: Preventing the model from processing PII (Personally Identifiable Information).
- Enforce Topic Control: Restricting the AI from discussing off-topic or restricted subjects (e.g., a customer service bot refusing to discuss politics).
Output Guardrails (Post-processing)
These scan the AI’s generated response before the user sees it. They check for:
- Hallucinations: Verifying facts against a trusted knowledge base (often using RAG: Retrieval-Augmented Generation).
- Toxicity and Bias: Ensuring the response isn’t offensive, discriminatory, or harmful.
- Formatting Compliance: Making sure the output follows a specific structure, such as valid JSON or a specific coding style.
| Layer | Purpose | Example |
| Foundational | Hard-coded rules or safety training built into the model. | Reinforcement Learning from Human Feedback (RLHF). |
| Architectural | Separate software modules that “check” the model. | NeMo Guardrails or Llama Guard. |
| Operational | Business-specific rules defined by the organization. | Hard-coded rules or safety training are built into the model. |
Why Are They Necessary?
Without guardrails, Large Language Models (LLMs) are essentially probabilistic engines. They predict the “most likely” next word, which may not always be the “most correct” or “safest” word. Guardrails provide:
- Reliability: They reduce the unpredictability of “black box” models.
- Brand Safety: They prevent AI from generating PR disasters or leaking proprietary secrets.
- Compliance: They ensure the AI adheres to regulations like GDPR or industry-specific legal standards.
Key Distinction: While Alignment (training the model to be “good”) happens during the model’s creation, Guardrails are active deployment tools that control the model’s behavior in the wild.